Deweloper ma 14 dni na reklamację poznaj swoje prawa!
Deweloper ma 14 dni na reklamację. Dowiedz się, jakie masz prawa, co oznacza brak odpowiedzi i jak działa rękojmia. Sprawdź nasz poradnik!
Klaudia Kucharska
18 października 2025
Deweloper ma 14 dni na reklamację. Dowiedz się, jakie masz prawa, co oznacza brak odpowiedzi i jak działa rękojmia. Sprawdź nasz poradnik!
Klaudia Kucharska
18 października 2025
Pszczelna.pl to portal, który łączy pasjonatów rynku nieruchomości. Nasz zespół autorów składa się z ekspertów, którzy dzielą się swoją wiedzą na temat najnowszych trendów, analiz rynkowych oraz praktycznych porad dla kupujących i sprzedających. Znajdziesz tu artykuły, które pomogą Ci podejmować świadome decyzje, niezależnie od tego, czy planujesz zakup nowego mieszkania, czy sprzedaż swojej nieruchomości. Zachęcamy do zgłębiania naszych treści i dołączenia do społeczności, która z pasją podchodzi do tematu nieruchomości!
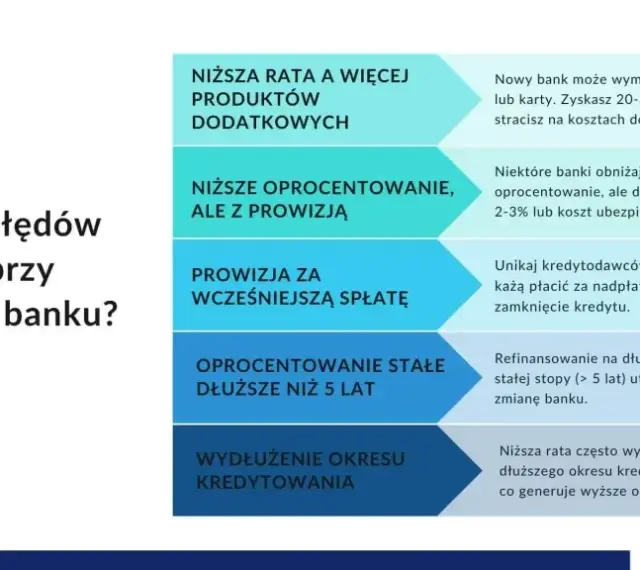
Dowiedz się, dlaczego deweloperzy ukrywają ceny mieszkań. Poznaj strategie, jak uzyskać informacje i skutecznie negocjować cenę.
Odbiór mieszkania od dewelopera? Poznaj prawa, listę kontrolną i procedurę odbioru. Zabezpiecz swoją inwestycję! Sprawdź nasz przewodnik.
O co zapytać dewelopera przed zakupem mieszkania? Sprawdź nasz przewodnik! Uniknij pułapek, zabezpiecz finanse i wybierz idealną nieruchomość.
Jakie pytania zadać deweloperowi? Skorzystaj z checklisty eksperta! Zapewnij sobie bezpieczny zakup mieszkania i uniknij pułapek. Sprawdź teraz!
Kompleksowy przewodnik po odbiorze mieszkania od dewelopera. Poznaj kroki, prawa i checklistę, by uniknąć błędów. Sprawdź teraz!

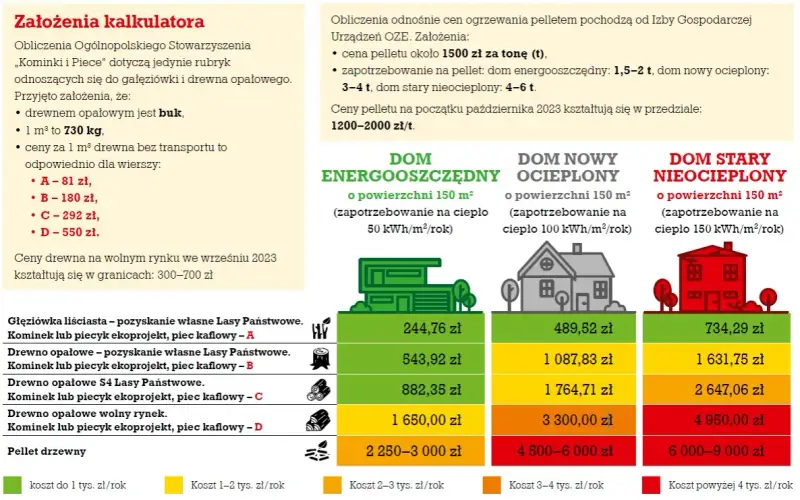
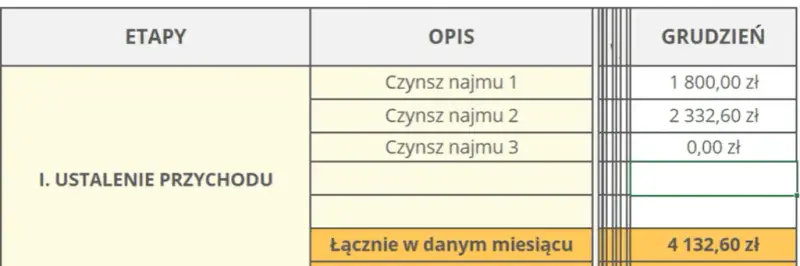
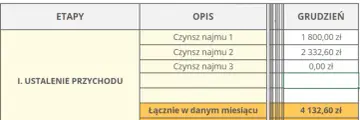
Oblicz realną stopę zwrotu z najmu mieszkania! Dowiedz się, jak uwzględnić wszystkie koszty, wzory ROI i ROE oraz uniknąć błędów. Sprawdź nasz poradnik.

Szukasz mieszkania w Turcji? Sprawdź aktualne ceny wynajmu, koszty (czynsz, aidat, media) i niezbędne formalności dla Polaków. Dowiedz się, jak się przygotować!

Planujesz wynajem mieszkania w Belgii? Sprawdź przewodnik po cenach, kaucjach, mediach i dodatkowych opłatach. Poznaj kluczowe czynniki wpływające na koszt i praktyczne porady.

Rozliczasz najem prywatny w 2026? Odkryj, jak płacić ryczałt od przychodów, jakie stawki obowiązują i kiedy złożyć PIT-28. Sprawdź nasz poradnik!